flatkey.ai Blog
Insights, product notes, and implementation guides for teams building on AI APIs.
Gateway Comparisons
Latest articles in Gateway Comparisons.
Read moreModel and Modality Playbooks
Latest articles in Model and Modality Playbooks.
Read moreBase URL and SDK Migration
Latest articles in Base URL and SDK Migration.
Read moreAI Gateway Architecture
Latest articles in AI Gateway Architecture.
Read moreCost, Billing, and Ops
Latest articles in Cost, Billing, and Ops.
Read moreTool Integrations
Latest articles in Tool Integrations.
Read moreReliability and Routing
Latest articles in Reliability and Routing.
Read moreEnterprise Controls and Trust
Latest articles in Enterprise Controls and Trust.
Read more
GPT Image 2 API Through Flatkey: Pricing, Models, and Request Checks
GPT Image 2 API access through Flatkey should start with a model-row check, not a copied code block. OpenAI documents gpt-image-2 as a current image generation model, and Flatkey's June 17, 2026 pricing snapshot lists GPT image-family rows. The useful question for a production team is narrower: whic

DeepSeek V4 Migration Checklist: Replace Deprecated Aliases Safely
DeepSeek V4 migration is now a deadline-driven cleanup task, not just a model upgrade. DeepSeek's official API docs say the older deepseek-chat and deepseek-reasoner aliases will be fully retired and inaccessible after July 24, 2026 at 15:59 UTC. The supported V4 model IDs are deepseek-v4-flash and

MiniMax API Access With One OpenAI-Compatible Router
MiniMax API access has two practical paths for teams that already use OpenAI-style clients. You can call MiniMax directly with the official MiniMax OpenAI SDK configuration, or you can evaluate MiniMax through a unified router workflow where one gateway base URL, one key, usage logs, pricing checks,

Qwen API Access With One OpenAI-Compatible Base URL
Qwen API access has two practical paths for teams that already use OpenAI-style clients. You can call Qwen directly through Alibaba Cloud Model Studio's DashScope OpenAI-compatible interface, or you can keep one Flatkey router base URL and use Qwen beside the other models your product already routes
Claude OpenAI SDK Compatibility: What Works and What Does Not
Claude OpenAI SDK compatibility is useful when your app already uses OpenAI's Python or JavaScript SDK and you want to evaluate Claude without rewriting the client layer. It is not the same as full OpenAI API parity, and Anthropic's own documentation draws that line clearly. There are two practical

Gemini API OpenAI Compatible Access Through a Router
Gemini API OpenAI compatible access is useful for two different migration paths. Google documents a direct OpenAI-compatible endpoint for Gemini, and Flatkey gives teams a router path when they want Gemini access inside the same one-key gateway they use for other models. The direct Google path is a
Sora 2 API Deprecation Watch: Routing Checks Before September 24, 2026
Sora 2 API demand is still high because developers are trying to answer a practical question: can a video generation workflow safely route production traffic through OpenAI's Sora models now? The short answer is risk-aware. As of June 12, 2026, OpenAI's video generation guide still documents the Vi
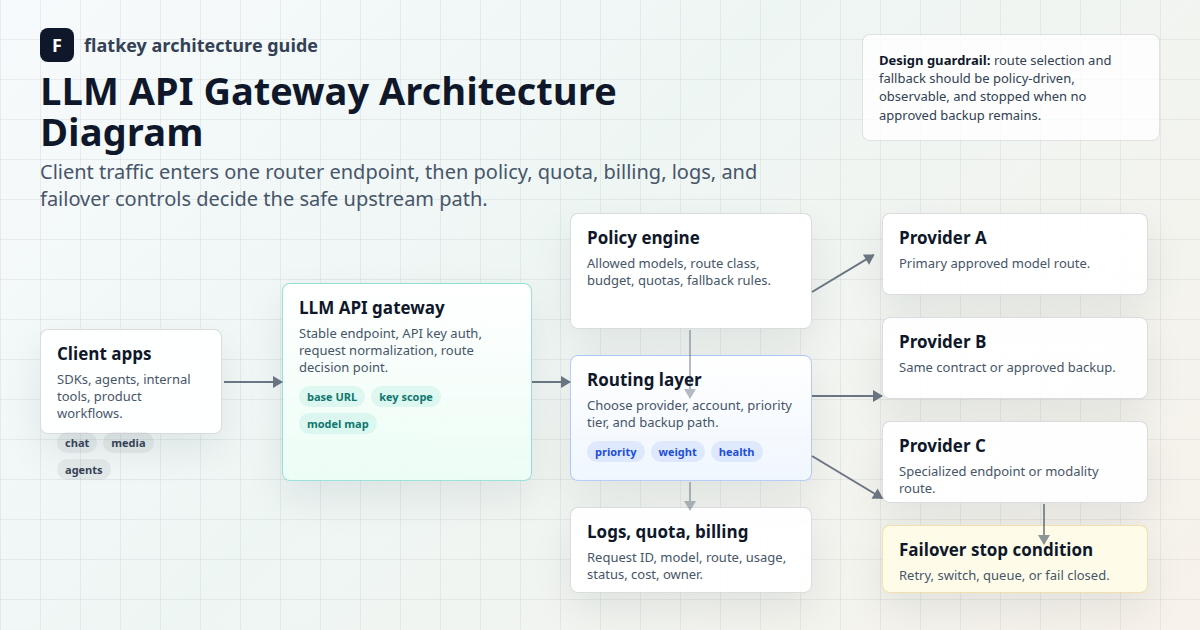
LLM API Gateway Architecture Diagram for Multi-Provider Routing and Failover
An LLM API gateway is the control plane between application code and multiple model providers. The useful architecture is not just a proxy URL. It has to authenticate callers, map models, apply policy, choose an upstream route, enforce quota, record usage, calculate cost, and decide what happens whe
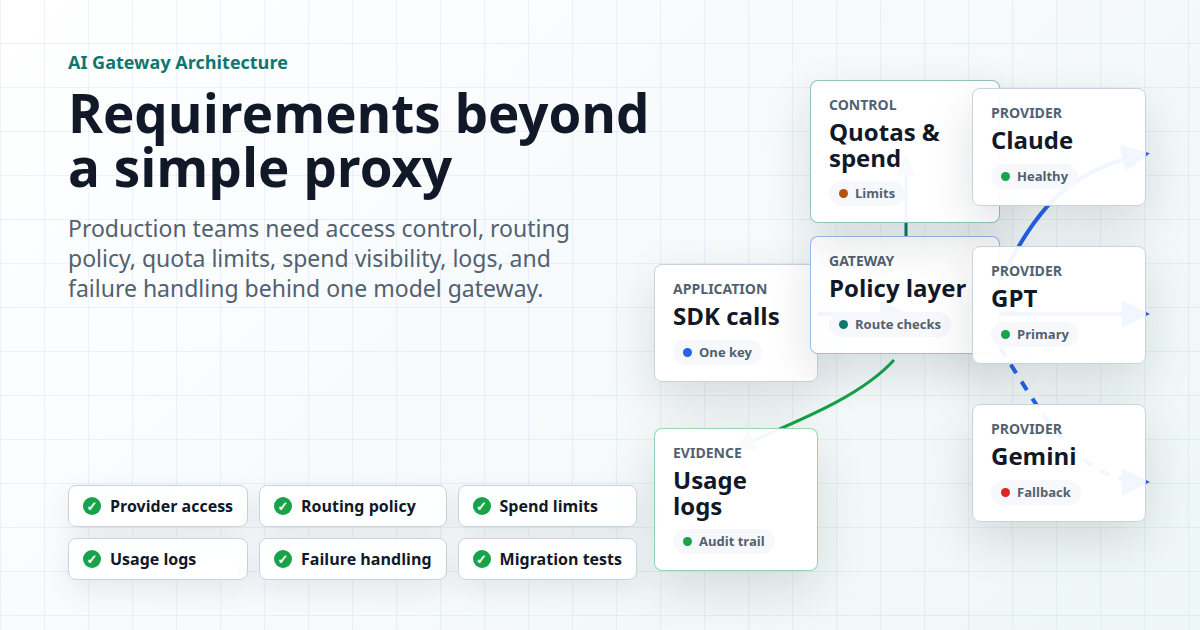
AI API Gateway Requirements: What Production Teams Need Beyond a Proxy
An AI API gateway becomes useful when it does more than forward HTTP requests. In production, the gateway has to control who can call which models, how traffic is routed, what happens when a provider fails, how quota and spend are enforced, and what logs remain after an incident. That is the practic
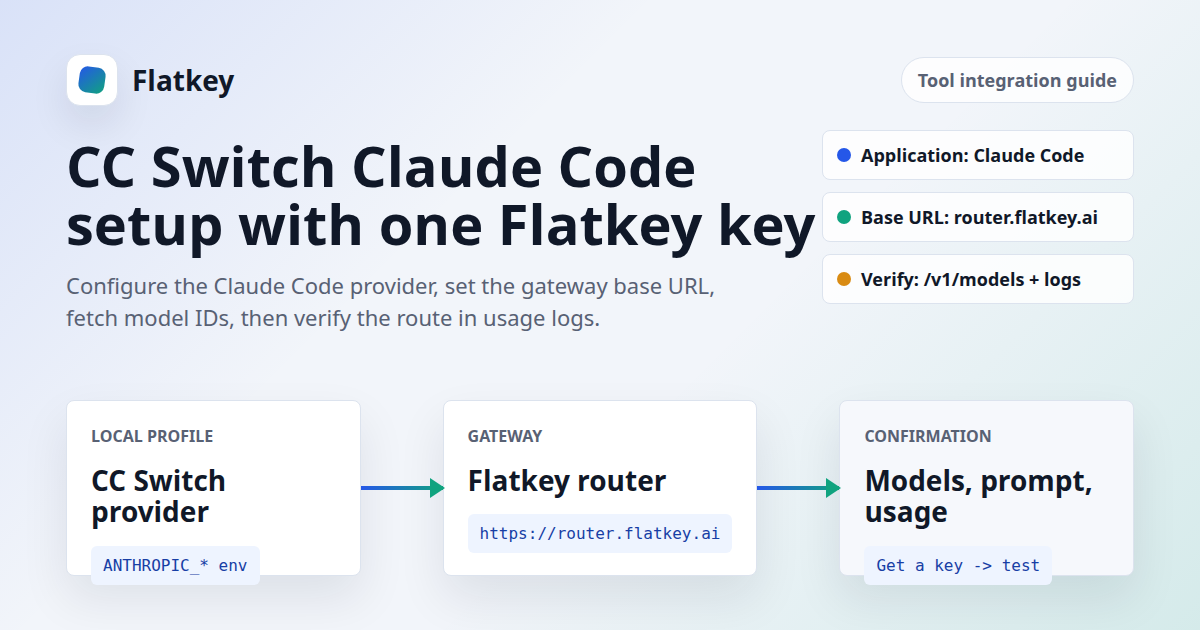
CC Switch Claude Code Setup With Flatkey and NewAPI
If you are searching for CC Switch Claude Code, you probably already have the coding assistant installed. The setup problem is narrower: you need CC Switch to write the right Claude Code provider config, use the right Flatkey key, point at the right base URL, pick models that your key can actually a
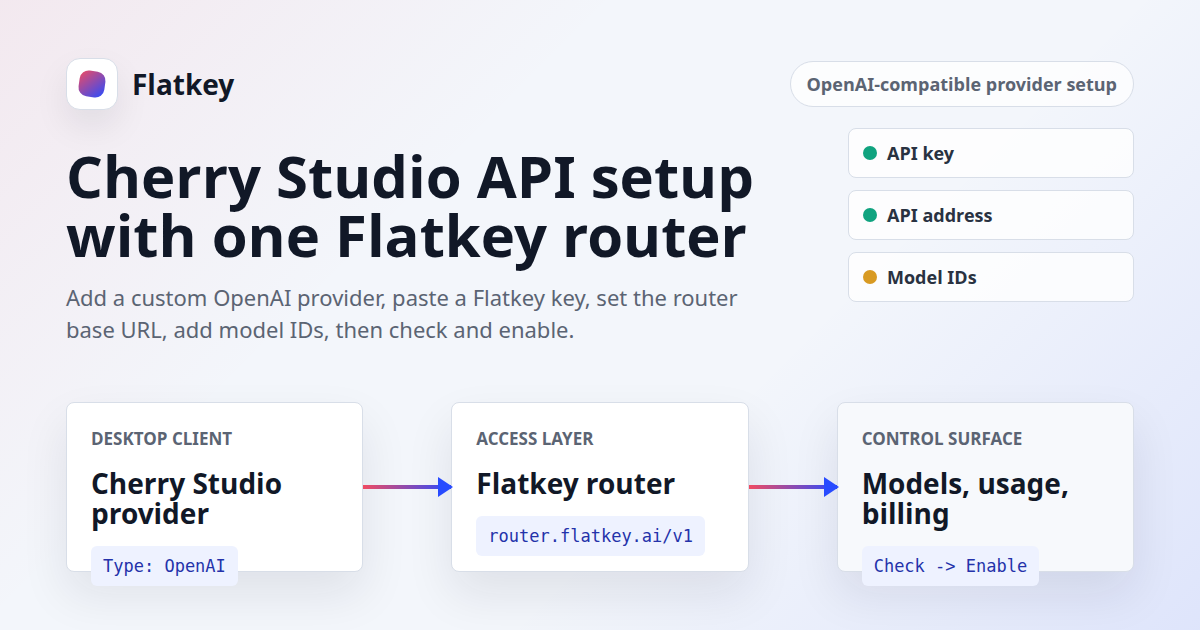
Cherry Studio API Setup: Add Flatkey as an OpenAI-Compatible Provider
If you are searching for Cherry Studio API setup, you probably already know which model router you want to use. The remaining job is practical: add a provider in Cherry Studio, paste the right API key, set the API address, add the model IDs you want, and confirm the provider is enabled. Flatkey fit

Claude API Proxy vs Multi-Model Router: When One Key Wins
Claude API proxy searches usually start with a narrow problem: a developer wants Claude access behind a different base URL, a shared key, or a gateway that works with Claude Code, CC Switch, or another Anthropic-compatible tool. That is a reasonable need. If your whole stack is Claude-only, a provid

AI API Load Balancing and Failover Behind One Key
AI API load balancing is the reliability layer between your application and the model providers that serve production traffic. It decides where each request goes, what happens when an upstream account is slow or unavailable, when to retry, when to switch, and how engineers prove the decision after a
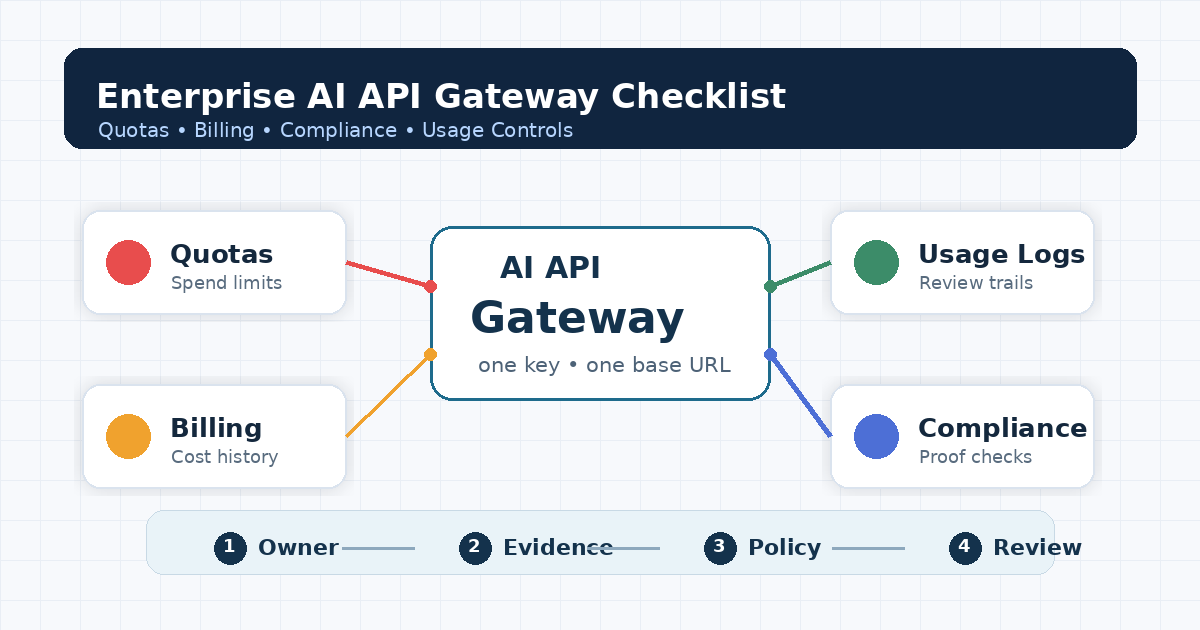
Enterprise AI API Gateway Checklist: Quotas, Billing, Compliance, and Usage Controls
An enterprise AI API gateway is not ready for procurement just because it can route prompts to several models. At review time, the buyer needs to see who owns access, how spend is limited, how usage is reviewed, how billing is reconciled, and which compliance documents can be verified before product

OpenAI-Compatible API Migration: Change Base URL to Flatkey
If your app already uses an OpenAI compatible API, moving to Flatkey should not start with a rewrite. The controlled path is smaller: get a Flatkey key, point your OpenAI-compatible SDK at https://router.flatkey.ai/v1, choose a model ID from the Flatkey catalog, and verify the first request in logs,

LiteLLM Alternatives: Managed One-Key Routing vs Self-Hosted LLM Proxy
If you are comparing LiteLLM alternatives, the real question is not only "Which tool can proxy LLM calls?" It is "Which parts of the gateway do we want to own?" LiteLLM is a strong choice when your team wants an open-source, self-hosted LLM proxy. Its docs position LiteLLM as a unified interface fo

AI Model Pricing Comparison: Token, Image, and Video Costs in One Dashboard
AI model pricing comparison gets messy as soon as your product uses more than one modality. Text models are often compared by input and output token rates. Image models add image input, output image tokens, quality settings, and edits. Video models may expose token-style rows, per-job rows, per-seco
OpenAI Image API Pricing: How to Budget GPT Image and Multimodal Generation Costs
OpenAI image API pricing is easy to misread if you treat every image request as one flat "cost per image." GPT Image pricing is token-based: text prompt tokens, image input tokens for edits or references, cached input when available, image output tokens, and in some GPT Image rows, text output token
Build faster with one AI gateway.
Use flatkey.ai to manage models, keys, billing, and observability from one API platform.
Get started