An LLM API gateway is the control plane between application code and multiple model providers. The useful architecture is not just a proxy URL. It has to authenticate callers, map models, apply policy, choose an upstream route, enforce quota, record usage, calculate cost, and decide what happens when a provider fails.
This guide gives platform engineers a practical LLM API gateway architecture diagram for multi-provider routing and failover. It uses public gateway patterns from Vercel and Pydantic as category references, then keeps Flatkey-specific claims limited to current public proof: one API key, an OpenAI-compatible router endpoint at https://router.flatkey.ai/v1, clear pricing, unified billing, a dashboard for keys, usage, and routing, automatic switching, and load balancing.
The goal is to help you review the design before production traffic depends on it. Use the diagram as a checklist for your own gateway, a vendor evaluation, or a Flatkey staging test.
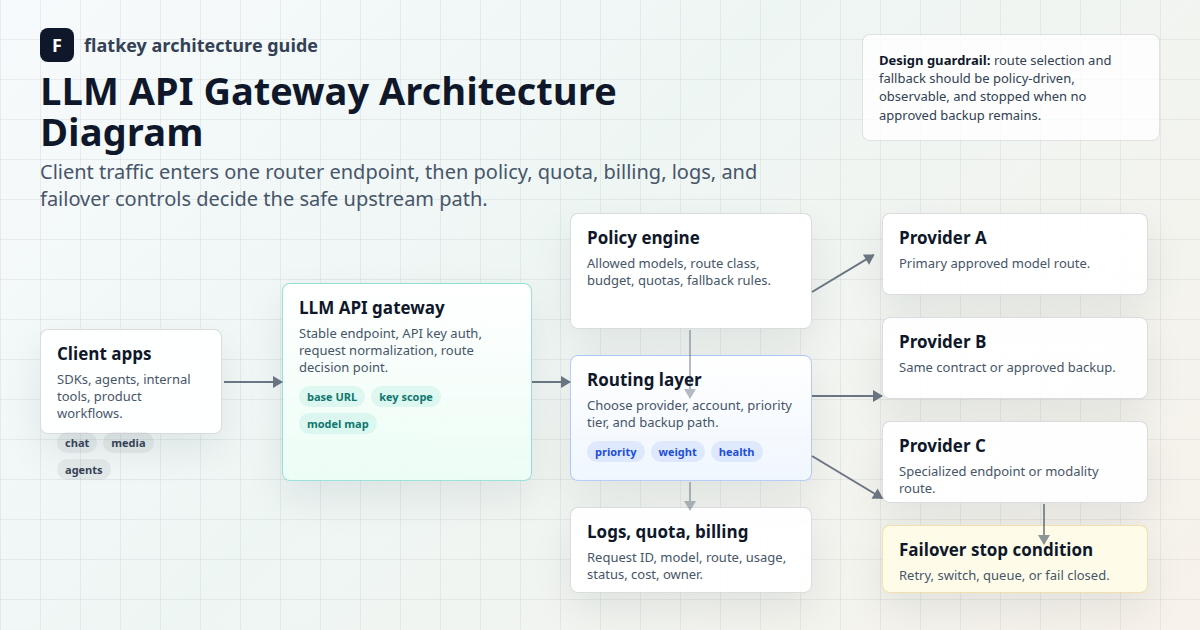
LLM API Gateway Architecture Diagram
The diagram shows the request path from client apps to upstream model providers. The center of the architecture is the LLM API gateway. Around it are the policy services that make routing safe to operate: key scope, model mapping, route class, quota ledger, billing, logs, health checks, and fallback rules.
| Layer | Responsibility | Design Question |
|---|---|---|
| Client apps | Send chat, responses, image, video, agent, or tool requests. | Which SDKs and endpoint formats must keep working? |
| Gateway endpoint | Receives requests through a stable base URL and API key. | Can applications migrate by changing only the key, base URL, or provider config? |
| Authentication and key scope | Identifies caller, team, app, environment, and allowed model set. | Can staging, production, and customer traffic be separated? |
| Policy engine | Applies model mapping, route class, budget, quota, and fallback rules. | Does policy explain why a request can or cannot use a route? |
| Router | Selects an upstream provider, account, model, or backup path. | Is routing based on approved policy rather than hidden magic? |
| Health and failover | Tracks provider errors, timeouts, retries, fallback, and stop conditions. | Which failures should retry, switch, queue, or fail closed? |
| Logs, quota, and billing | Records model, route, status, token or media units, cost, owner, and key. | Can engineers and finance trace a request after an incident? |
| Upstream providers | Serve the selected model through provider-native or compatible APIs. | Which providers are approved for each traffic class? |
How A Request Moves Through The Gateway
A production LLM API gateway should make the request path easy to explain. If your team cannot draw the path, you probably cannot debug the path during an outage or billing review.
- The client sends a request. The app calls the gateway with a model name, endpoint, messages or media input, and an application API key.
- The gateway authenticates the key. The key maps to an owner, environment, quota, allowed model set, and logging policy.
- The policy engine classifies traffic. The request is tagged as customer chat, background work, evaluation, media generation, coding tool traffic, or another route class.
- The router chooses a candidate route. It checks model mapping, provider availability, allowed upstream accounts, cost policy, quota state, and any configured priority or weight.
- The gateway sends the upstream request. Depending on the provider and endpoint, this may preserve an OpenAI-compatible request shape or use a provider-native protocol.
- The response is normalized where possible. The gateway returns the expected response shape, error, stream, or job reference to the client.
- The request is recorded. Logs capture route, model, status, latency, usage units, cost estimate, key, and owner so the team can debug and reconcile spend.
This is why the OpenAI-compatible API migration step is only one part of the architecture. Changing a base URL gets traffic to the gateway. Production readiness depends on policy, routing, quota, billing, logs, and fallback behavior after that.
Routing Policy Comes Before Failover
The most common architecture mistake is treating failover as a universal good. An LLM API gateway should not blindly replay every failed request against every provider. It should first decide whether the backup path is allowed for that traffic class.
Public gateway docs show why this distinction matters. Pydantic documents routing groups where providers can have priority, weight, and active state, allowing failover between providers serving the same model or load balancing across same-priority members. Vercel positions AI Gateway around routing, billing, observability, many models, and provider/model routing with fallbacks. Those patterns are useful references, but your production policy still has to define what is acceptable for your workload.
| Traffic Class | Primary Routing Rule | Failover Rule |
|---|---|---|
| Customer-facing chat | Use only approved model families and providers. | Switch only to an approved equivalent, or return a controlled error. |
| Background summarization | Prefer cost and throughput when quality requirements are stable. | Retry, queue, or use a lower-cost approved model if output quality remains acceptable. |
| Evaluation and benchmarks | Keep model identity stable. | Fail closed; hidden fallback makes results hard to compare. |
| Media generation | Respect endpoint shape, job lifecycle, media policy, and budget. | Fail closed unless the alternate model has the same approved output contract. |
| Agent workflows | Respect tool support, context limits, data boundary, and audit needs. | Fallback only when tool behavior and data handling stay valid. |
Flatkey's public copy says it routes multiple upstream accounts with automatic switching and load balancing. Use that as the product starting point, then define which of your traffic classes can switch automatically and which must fail closed.
Failover Needs A Stop Condition
Every LLM API gateway failover design needs a stop condition. Without one, a malformed request can become a cascade of repeated invalid calls, duplicated spend, confusing logs, and inconsistent user behavior.
A practical failure ladder looks like this:
- Reject before upstream: fail closed for invalid auth, forbidden model, exceeded quota, unsupported endpoint, or missing required parameters.
- Retry same route: retry only when the error is plausibly transient, such as a network timeout or selected upstream 5xx.
- Switch same contract: use another account, region, or provider path only if it serves the same approved model contract.
- Use approved backup: move to another model only when product, quality, compliance, and budget owners approve the backup.
- Queue or degrade: delay non-urgent work when immediate fallback would be expensive or risky.
- Return a controlled error: stop when policy says no safe route remains.
The AI API load balancing and failover guide covers this in more detail. In architecture review, the important question is whether each transition is explicit and observable.
Quota, Billing, And Logs Are Part Of The Request Path
Model traffic is not billed like ordinary HTTP traffic. A single LLM API gateway may have to account for input tokens, output tokens, cached tokens, reasoning tokens, image units, video duration, tool calls, retries, and provider-specific quota units. If billing and quota are treated as a nightly report, the gateway cannot prevent runaway usage in the moment.
Put quota and billing close to routing policy:
- Check the caller's remaining budget before forwarding expensive requests.
- Block or warn on routes with missing pricing data when spend limits matter.
- Record the selected model, endpoint family, upstream route, key, owner, status, and usage units.
- Separate retries and fallback calls in logs so one user request does not hide multiple provider attempts.
- Make staging and production keys visible as different cost centers.
- Export enough data for finance, support, and incident review.
Flatkey's current public positioning includes clear pricing, unified billing, usage visibility, quota limits, and one dashboard for keys, usage, and routing. A publish-day pricing API snapshot returned 656 model rows and supported endpoint metadata for OpenAI-compatible, OpenAI Responses, Anthropic, Gemini, image generation, and video generation traffic. Treat that as dated evidence, then verify your exact model and unit on the live pricing page.
Where Flatkey Fits In This Architecture
Flatkey is designed to reduce provider-account sprawl behind one key. In this LLM API gateway architecture, Flatkey maps to the hosted gateway endpoint, provider access layer, dashboard, usage/billing layer, and routing layer.
A careful Flatkey staging test should look like this:
- Create a non-production key in the Flatkey dashboard.
- Point one client at
https://router.flatkey.ai/v1. - Run a known-good request for the endpoint family you need.
- Confirm the request appears in usage logs with model, status, units, and cost evidence.
- Review the live pricing page for the selected model and billing unit.
- Define which traffic classes can use automatic switching or load balancing.
- Run one safe failure test, or document why failure simulation is not allowed in staging.
Do not infer an uptime SLA, latency guarantee, exact routing algorithm, or guaranteed provider availability from this article. The architecture tells you what to validate; your staging evidence tells you whether a specific rollout is ready.
Implementation Checklist
Before sending production traffic through an LLM API gateway, make sure the architecture has these controls in place:
| Checklist Item | Pass Condition |
|---|---|
| Base URL and SDK migration | At least one staging request succeeds through the gateway with the intended SDK or client. |
| Model and endpoint mapping | Every production endpoint family has an approved model, protocol, and owner. |
| Key scope | Keys are separated by app, environment, team, or customer where needed. |
| Routing policy | Traffic classes define allowed primary routes and backup routes. |
| Failover stop condition | The gateway knows when to retry, switch, queue, and fail closed. |
| Quota and budget checks | Limits can stop or constrain expensive traffic before it reaches an upstream provider. |
| Logs and observability | Request, route, model, owner, status, usage, and cost evidence can be reviewed after the fact. |
| Rollback | The app can return to its prior provider config if the gateway rollout fails. |
For a broader requirements view, start with the AI API gateway checklist. For platform comparison work, the OpenRouter alternatives guide shows how managed gateway tradeoffs differ from provider marketplaces and self-managed routing layers.
FAQ
What is an LLM API gateway?
An LLM API gateway is a control layer between applications and model providers. It can centralize API keys, model access, routing, quota, billing, logs, and failover policy for LLM traffic.
What should an LLM API gateway architecture include?
An LLM API gateway architecture should include client apps, a stable gateway endpoint, authentication, key scope, policy checks, model mapping, provider routing, health checks, failover rules, quota, billing, logs, and upstream providers.
Is failover always safe for LLM traffic?
No. Failover is safe only when the backup route preserves the approved model contract, data boundary, endpoint behavior, quality expectations, and cost policy. Some traffic should fail closed instead of switching.
How is an LLM API gateway different from a normal API gateway?
A normal API gateway handles general API traffic. An LLM API gateway adds model-aware concerns such as provider formats, token and media usage, model mapping, fallback policy, spend controls, prompt/response observability, and AI-specific routing.
Where does Flatkey fit in the diagram?
Flatkey fits as the hosted gateway, router, provider-access, usage, billing, and dashboard layer. Its public copy supports one API key, https://router.flatkey.ai/v1, clear pricing, unified billing, usage/routing visibility, automatic switching, and load balancing.
Final Takeaway
A production LLM API gateway should make model traffic easier to control, not harder to explain. The architecture needs a stable endpoint, scoped keys, model mapping, policy checks, routing rules, quota and billing controls, logs, and a failover stop condition.
Flatkey gives teams one key, an OpenAI-compatible router endpoint, and one dashboard for model access and operations. To test the architecture with your own staging workload, get a key and verify the request path before moving production traffic.