Reliability and Routing
Latest articles in Reliability and Routing.
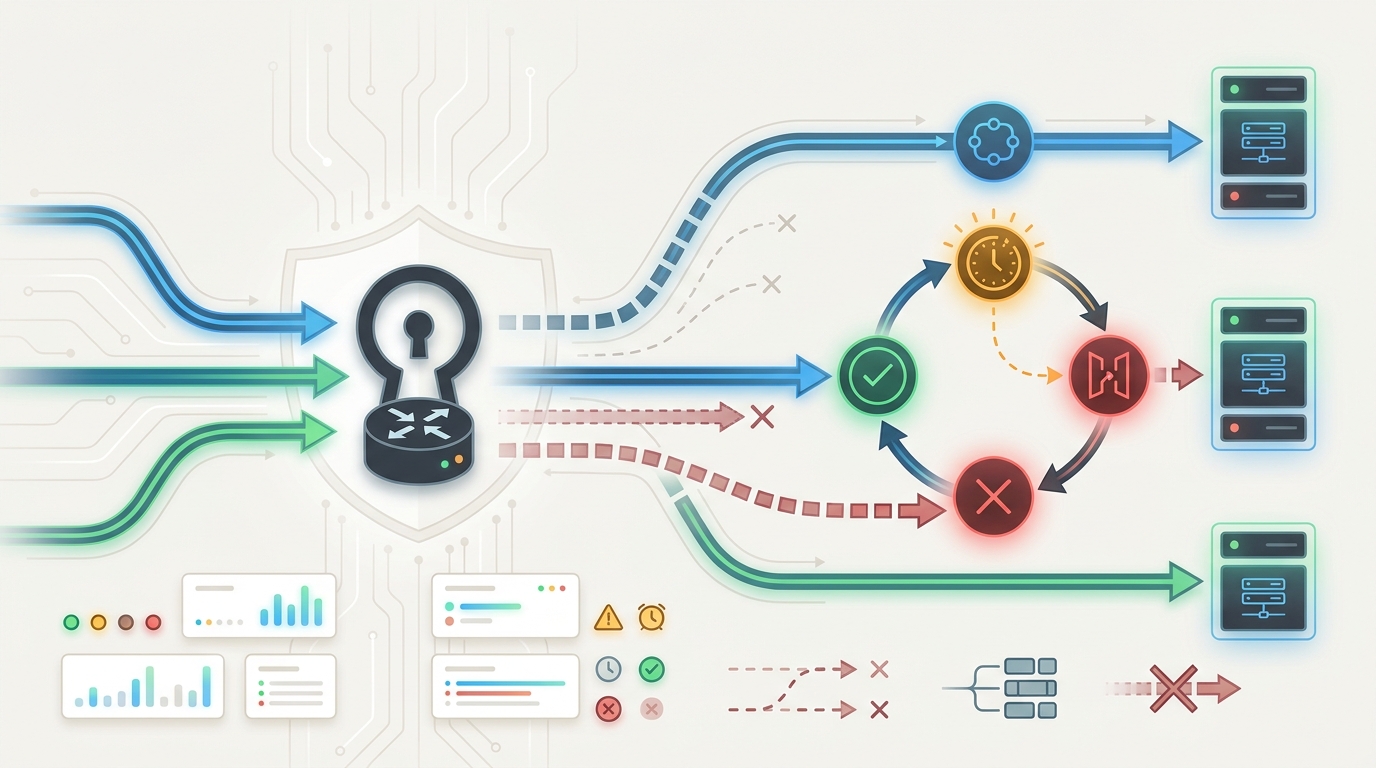
Circuit Breakers for LLM API Gateways: Protect Apps From Provider Failure Loops
An LLM API gateway circuit breaker stops an application from repeatedly sending traffic into a route that is already failing. Without that guardrail, a timeout can trigger retries, retries can trigger fallback attempts, fallback attempts can trigger more provider errors, and the app can turn one ups

Model Fallback Checklist: Quality, Cost, Tools, and Compliance Boundaries
Model fallback checklist work starts before a router switches traffic. A fallback model can save a request when the primary route fails, but it can also change answer quality, token cost, tool behavior, streaming semantics, data handling, and incident visibility. Treat fallback as an evaluated produ
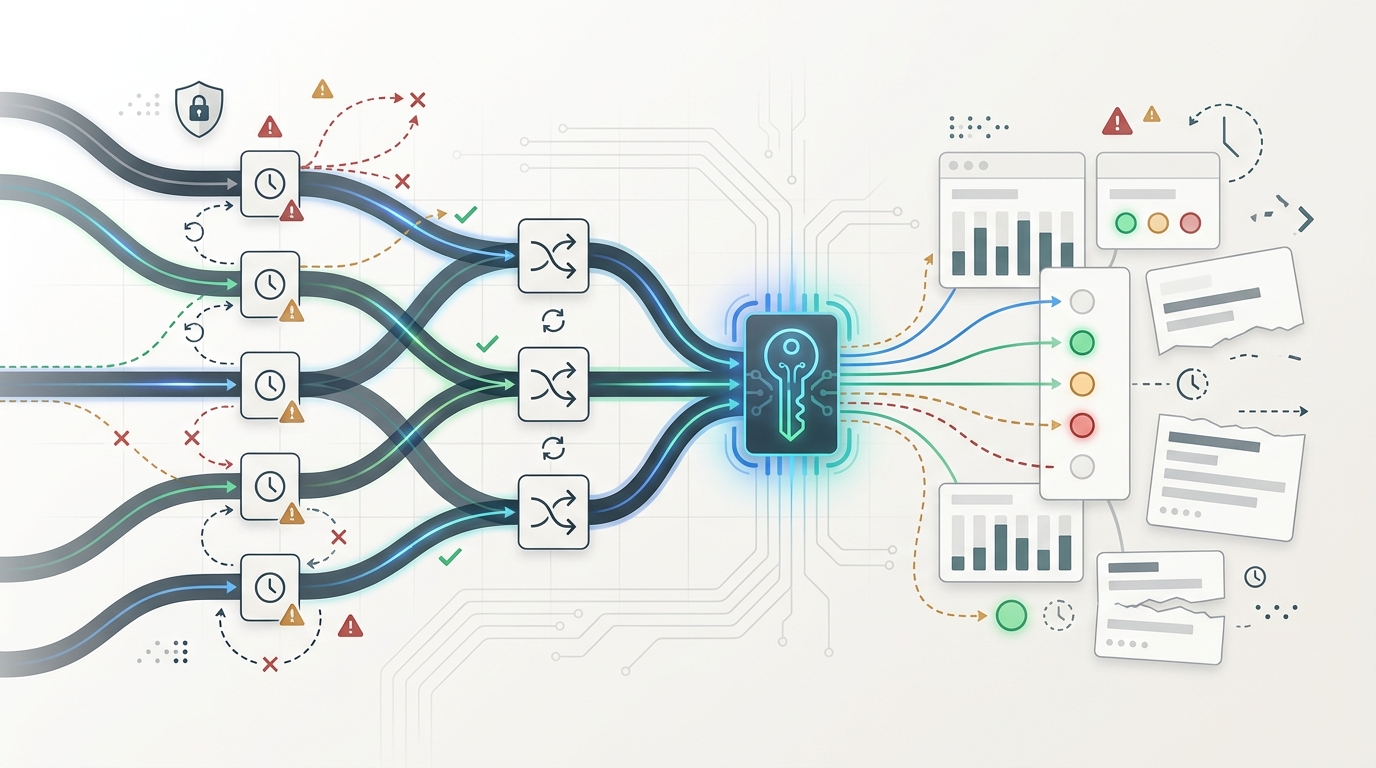
Streaming AI API Reliability: SSE, Timeouts, and Router-Level Failure Modes
Streaming AI API reliability is the set of tests and operating rules that prove a streamed model response can start quickly, keep flowing, survive normal network behavior, and fail in a way your product can explain. It is not enough for a gateway, SDK, or provider to support stream: true. Production
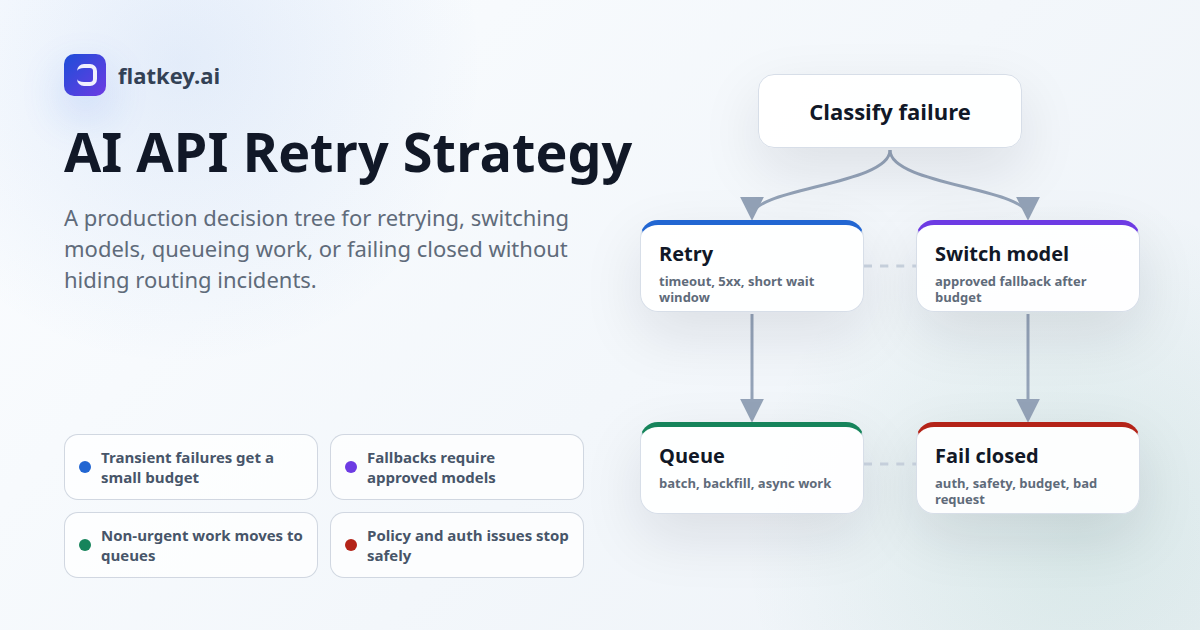
AI API Retry Strategy: When to Retry, Switch Models, Queue, or Fail Closed
AI API retry strategy is the policy that decides what your application should do after a model request fails, slows down, or returns a partial result. The wrong policy is expensive: retry every error and you multiply quota pressure; switch models too early and you change answer quality; queue intera

AI API Observability Logs: What to Capture for Model Routing Incidents
AI API observability is what lets an engineering team reconstruct a model routing incident without guessing. A user reports a timeout, a fallback model answers differently, a provider returns 429, or spend jumps after an upstream switch. The incident review needs more than a raw prompt and a status

AI API Load Balancing and Failover Behind One Key
AI API load balancing is the reliability layer between your application and the model providers that serve production traffic. It decides where each request goes, what happens when an upstream account is slow or unavailable, when to retry, when to switch, and how engineers prove the decision after a
Build faster with one AI gateway.
Use flatkey.ai to manage models, keys, billing, and observability from one API platform.
Get started