Model and Modality Playbooks
Latest articles in Model and Modality Playbooks.

Imagen API Pricing and Routing Checks for OpenAI-Compatible Workflows
Imagen API pricing looks simple when you only read the per-image row. In a production image workflow, the real decision is broader: which Google image model is current, whether an Imagen row is deprecated, which route family your gateway exposes, how the dashboard records the request, and whether th

Veo API Access Checklist for Multi-Provider Video Routing
Veo API access looks simple if you only read the model name. In production, it is a video workflow with model lifecycle checks, per-second pricing, async operations, resolution choices, retry costs, and route-level observability. If your team is comparing Veo with Seedance, Sora-style routes, or ano
GPT Image 2 API Through Flatkey: Pricing, Models, and Request Checks
GPT Image 2 API access through Flatkey should start with a model-row check, not a copied code block. OpenAI documents gpt-image-2 as a current image generation model, and Flatkey's June 17, 2026 pricing snapshot lists GPT image-family rows. The useful question for a production team is narrower: whic

DeepSeek V4 Migration Checklist: Replace Deprecated Aliases Safely
DeepSeek V4 migration is now a deadline-driven cleanup task, not just a model upgrade. DeepSeek's official API docs say the older deepseek-chat and deepseek-reasoner aliases will be fully retired and inaccessible after July 24, 2026 at 15:59 UTC. The supported V4 model IDs are deepseek-v4-flash and

MiniMax API Access With One OpenAI-Compatible Router
MiniMax API access has two practical paths for teams that already use OpenAI-style clients. You can call MiniMax directly with the official MiniMax OpenAI SDK configuration, or you can evaluate MiniMax through a unified router workflow where one gateway base URL, one key, usage logs, pricing checks,

Qwen API Access With One OpenAI-Compatible Base URL
Qwen API access has two practical paths for teams that already use OpenAI-style clients. You can call Qwen directly through Alibaba Cloud Model Studio's DashScope OpenAI-compatible interface, or you can keep one Flatkey router base URL and use Qwen beside the other models your product already routes
Claude OpenAI SDK Compatibility: What Works and What Does Not
Claude OpenAI SDK compatibility is useful when your app already uses OpenAI's Python or JavaScript SDK and you want to evaluate Claude without rewriting the client layer. It is not the same as full OpenAI API parity, and Anthropic's own documentation draws that line clearly. There are two practical

Gemini API OpenAI Compatible Access Through a Router
Gemini API OpenAI compatible access is useful for two different migration paths. Google documents a direct OpenAI-compatible endpoint for Gemini, and Flatkey gives teams a router path when they want Gemini access inside the same one-key gateway they use for other models. The direct Google path is a
Sora 2 API Deprecation Watch: Routing Checks Before September 24, 2026
Sora 2 API demand is still high because developers are trying to answer a practical question: can a video generation workflow safely route production traffic through OpenAI's Sora models now? The short answer is risk-aware. As of June 12, 2026, OpenAI's video generation guide still documents the Vi

Claude API Proxy vs Multi-Model Router: When One Key Wins
Claude API proxy searches usually start with a narrow problem: a developer wants Claude access behind a different base URL, a shared key, or a gateway that works with Claude Code, CC Switch, or another Anthropic-compatible tool. That is a reasonable need. If your whole stack is Claude-only, a provid

DeepSeek API Access Through an OpenAI-Compatible Router
If you need DeepSeek API access inside a product that already uses OpenAI-style SDKs, the cleanest migration path is usually not a full client rewrite. It is a base URL, API key, and model-ID decision. DeepSeek's official API docs say the API uses formats compatible with OpenAI and Anthropic. As of
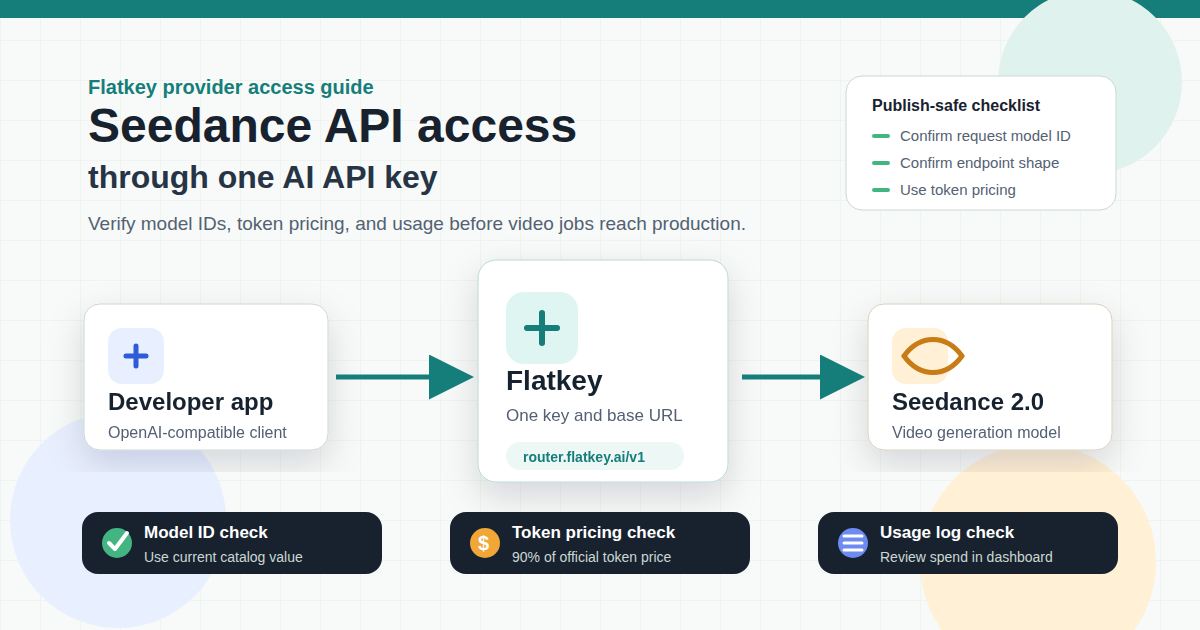
Seedance 2.0 API Access and Pricing Through One AI API Key
The fastest way to evaluate the Seedance API is not just to find a model endpoint. You also need a clean way to verify model IDs, compare token pricing, manage credentials, and keep video-generation spend visible once a test script becomes a production workflow. Flatkey is built for that access lay
Build faster with one AI gateway.
Use flatkey.ai to manage models, keys, billing, and observability from one API platform.
Get started