flatkey.ai Blog
Insights, product notes, and implementation guides for teams building on AI APIs.
Gateway Comparisons
Latest articles in Gateway Comparisons.
Read moreModel and Modality Playbooks
Latest articles in Model and Modality Playbooks.
Read moreBase URL and SDK Migration
Latest articles in Base URL and SDK Migration.
Read moreAI Gateway Architecture
Latest articles in AI Gateway Architecture.
Read moreCost, Billing, and Ops
Latest articles in Cost, Billing, and Ops.
Read moreTool Integrations
Latest articles in Tool Integrations.
Read moreReliability and Routing
Latest articles in Reliability and Routing.
Read moreEnterprise Controls and Trust
Latest articles in Enterprise Controls and Trust.
Read more
AI API Vendor Risk Assessment: Questions for Multi-Model Gateways
AI API vendor risk assessment gets complicated when the vendor is a multi-model gateway instead of a single model provider. The buyer is not only approving one API endpoint. The buyer is approving a request path that may include a gateway account, API keys, model routes, fallback behavior, usage log
SOC 2 AI API Gateway Evidence: What to Verify Before Procurement
SOC 2 AI API gateway review should start before the buyer asks for a security packet. The procurement question is not "do you have a badge?" It is whether the gateway, model routes, logs, keys, billing records, support process, and downstream providers can be matched to evidence that a security revi

GDPR AI API Gateway Checklist: Data Boundaries, Logs, and Vendor Review
GDPR AI API gateway review starts with a simple question: can you explain where personal data can enter, which service sees it, what is logged, how long evidence remains, and which vendor terms govern the request path? That question is harder for AI APIs than for a normal SaaS integration. One user
AI API Audit Logs: What Security Reviewers Ask For
AI API audit logs are the evidence layer behind a security review. Reviewers are not only asking whether an app called a model. They want to know who made the request, which key or project was used, what model and provider handled it, whether sensitive payloads were stored, how long records are reta

Key Rotation for AI API Gateways: Rotate One Router Key Without Breaking Apps
AI API key rotation is easy when one script uses one provider key. It is harder when production apps call many AI models through one router key, because a bad cutover can break chat, embeddings, image generation, tool calls, batch jobs, and internal copilots at the same time. The safe pattern is to
Circuit Breakers for LLM API Gateways: Protect Apps From Provider Failure Loops
An LLM API gateway circuit breaker stops an application from repeatedly sending traffic into a route that is already failing. Without that guardrail, a timeout can trigger retries, retries can trigger fallback attempts, fallback attempts can trigger more provider errors, and the app can turn one ups

Model Fallback Checklist: Quality, Cost, Tools, and Compliance Boundaries
Model fallback checklist work starts before a router switches traffic. A fallback model can save a request when the primary route fails, but it can also change answer quality, token cost, tool behavior, streaming semantics, data handling, and incident visibility. Treat fallback as an evaluated produ
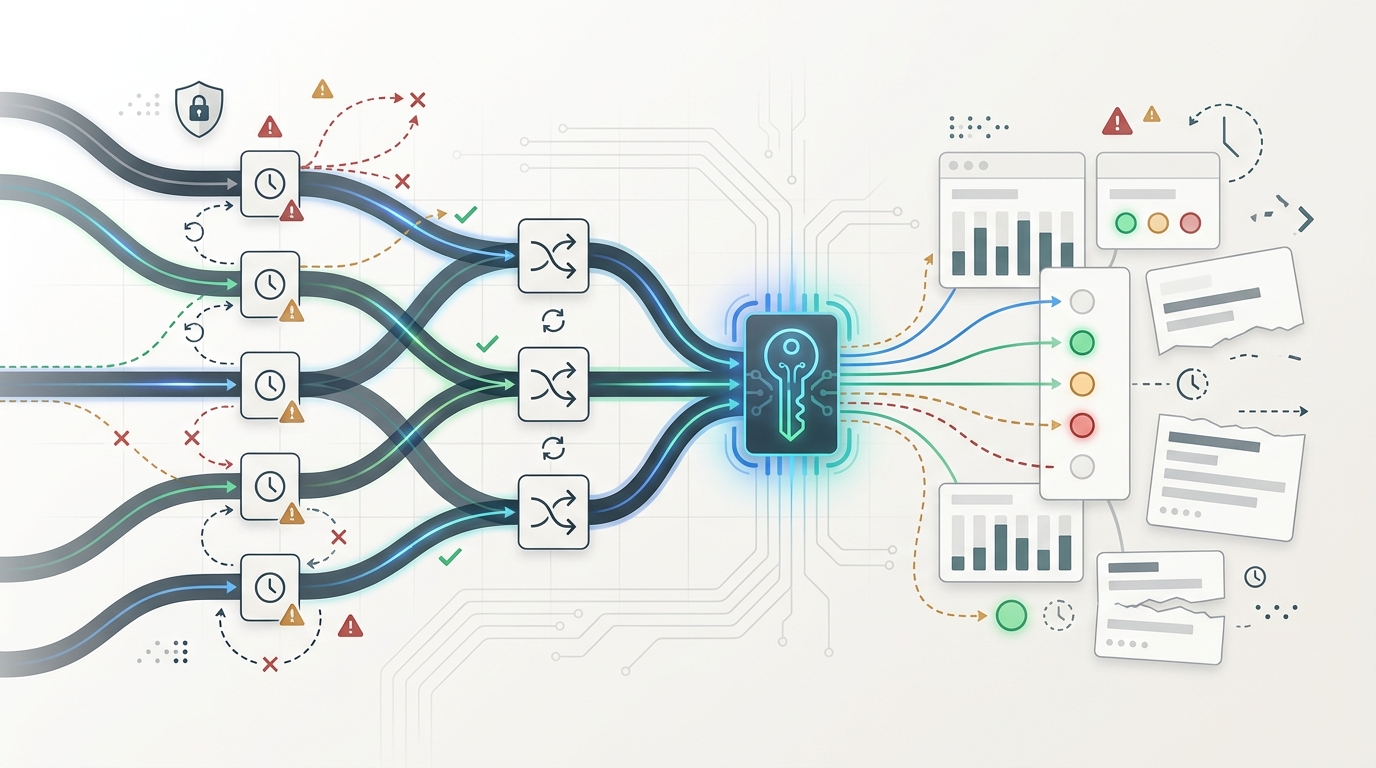
Streaming AI API Reliability: SSE, Timeouts, and Router-Level Failure Modes
Streaming AI API reliability is the set of tests and operating rules that prove a streamed model response can start quickly, keep flowing, survive normal network behavior, and fail in a way your product can explain. It is not enough for a gateway, SDK, or provider to support stream: true. Production
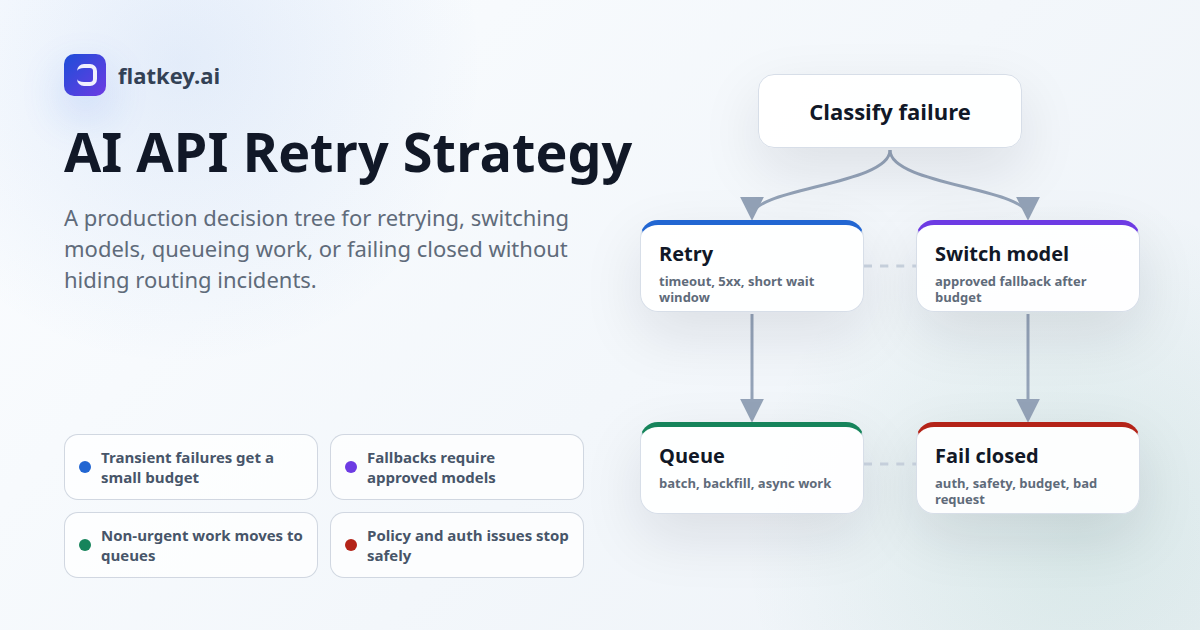
AI API Retry Strategy: When to Retry, Switch Models, Queue, or Fail Closed
AI API retry strategy is the policy that decides what your application should do after a model request fails, slows down, or returns a partial result. The wrong policy is expensive: retry every error and you multiply quota pressure; switch models too early and you change answer quality; queue intera

AI API Observability Logs: What to Capture for Model Routing Incidents
AI API observability is what lets an engineering team reconstruct a model routing incident without guessing. A user reports a timeout, a fallback model answers differently, a provider returns 429, or spend jumps after an upstream switch. The incident review needs more than a raw prompt and a status

AI API Cost Attribution by Team: From One Key to Accountable Usage
AI API cost attribution is the operating practice of connecting every model request and every billing unit to the team, product area, environment, workflow, or customer that created the spend. It turns "the AI bill went up" into "support automation, the evaluation pipeline, or one customer-facing fe
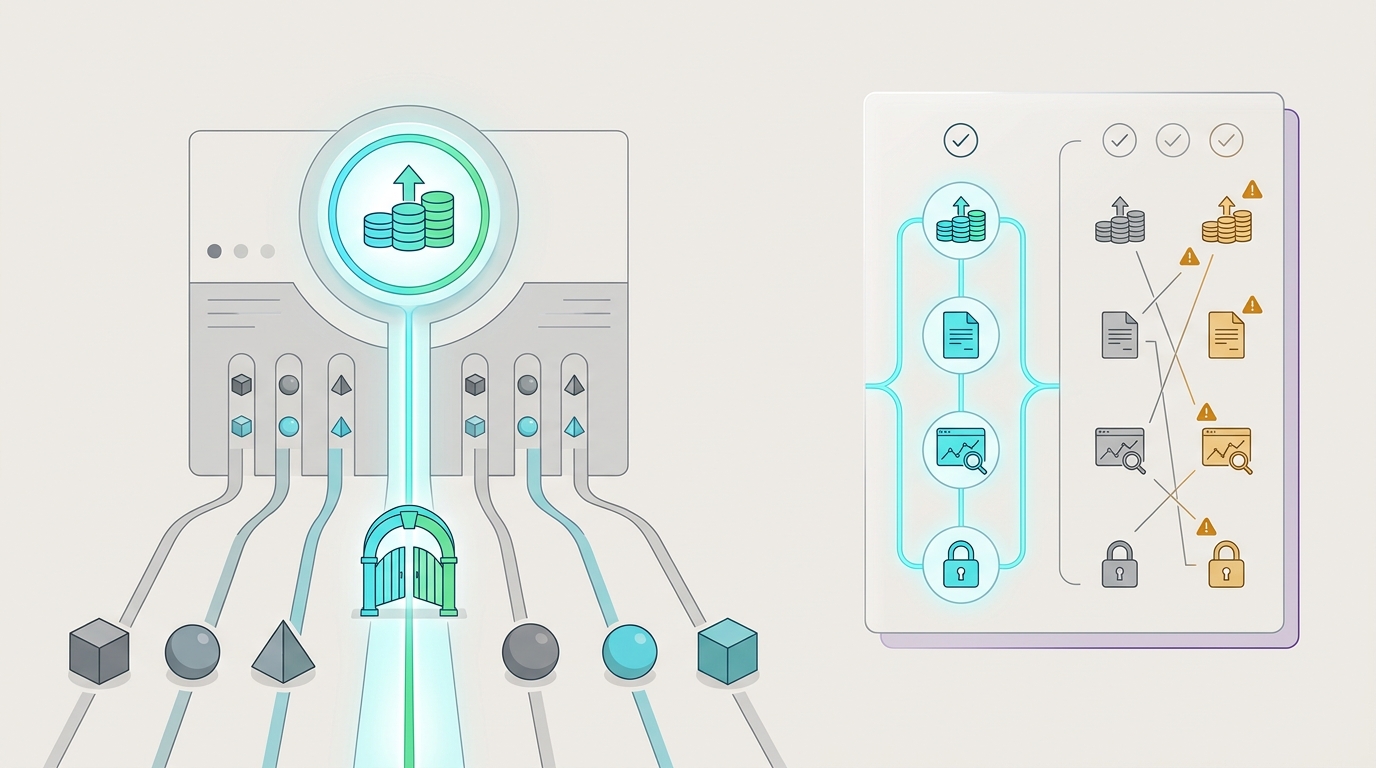
Prepaid AI API Billing vs Direct Provider Accounts: Operational Tradeoffs
prepaid AI API billing is a balance-first way to operate model spend: add funds once, route usage through a gateway, review consumption in one place, and keep finance from reconciling a separate account for every model provider. Direct provider accounts are the opposite operating pattern: each team
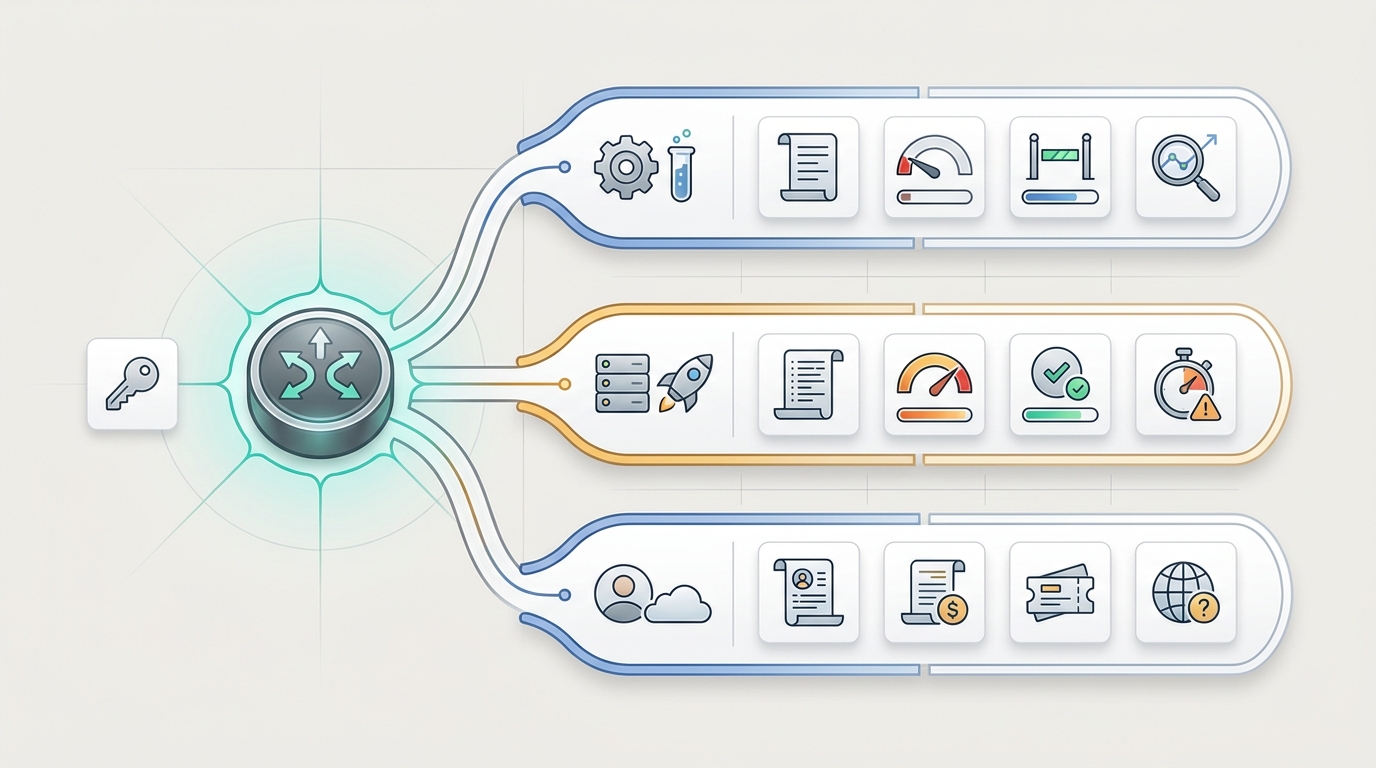
Per-Key AI Usage Tracking: Separate Staging, Production, and Customer Traffic
per-key AI usage tracking is the operating practice of assigning each AI API key a clear owner, environment, workflow, and traffic class, then reviewing usage, cost, errors, and quota events by that key. It is the difference between knowing that "the AI account spent more this week" and knowing that
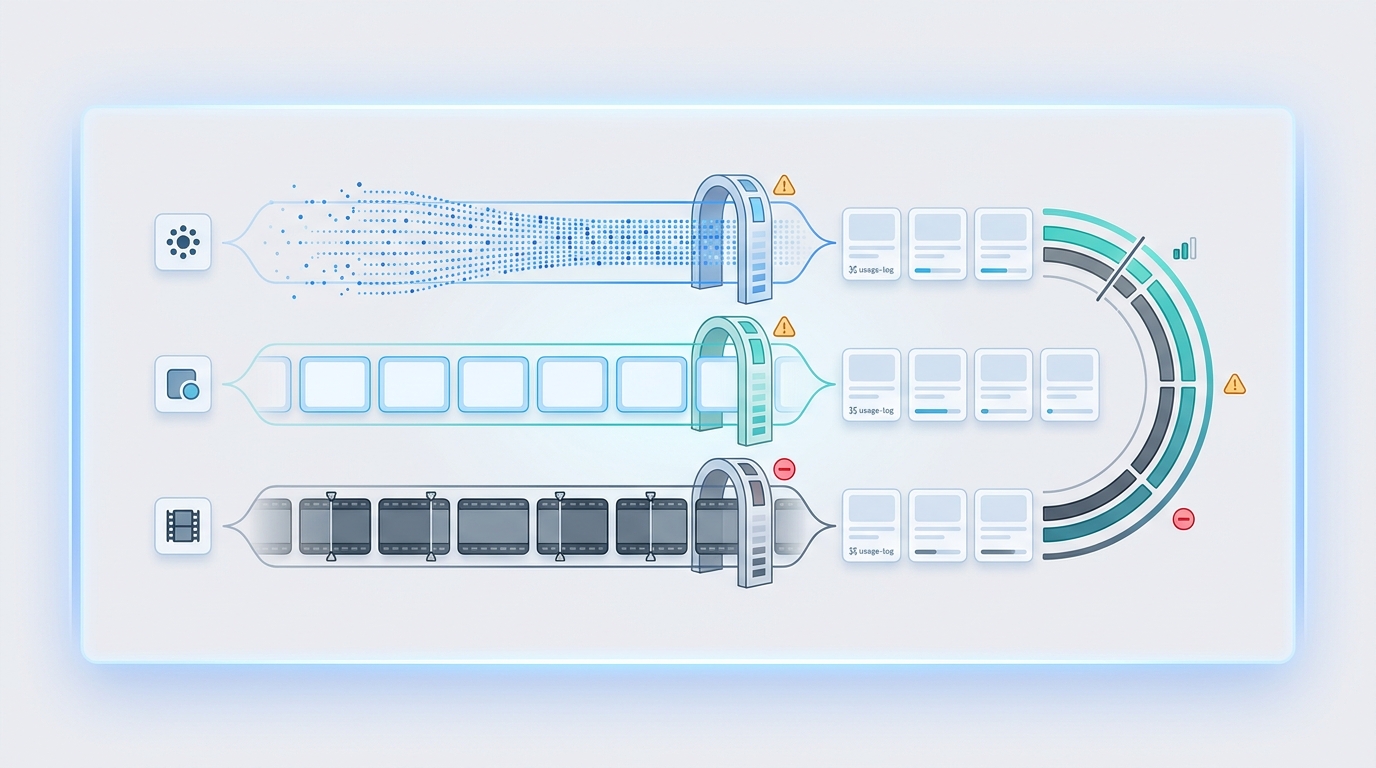
AI API Quota Management: Prevent Runaway Token, Image, and Video Spend
AI API quota management is the operating layer that keeps model experiments from turning into runaway token, image, and video bills. Rate limits protect throughput. Quotas protect budget, ownership, and launch safety by deciding how much a key, team, workflow, environment, model, or modality is allo

Imagen API Pricing and Routing Checks for OpenAI-Compatible Workflows
Imagen API pricing looks simple when you only read the per-image row. In a production image workflow, the real decision is broader: which Google image model is current, whether an Imagen row is deprecated, which route family your gateway exposes, how the dashboard records the request, and whether th

Veo API Access Checklist for Multi-Provider Video Routing
Veo API access looks simple if you only read the model name. In production, it is a video workflow with model lifecycle checks, per-second pricing, async operations, resolution choices, retry costs, and route-level observability. If your team is comparing Veo with Seedance, Sora-style routes, or ano
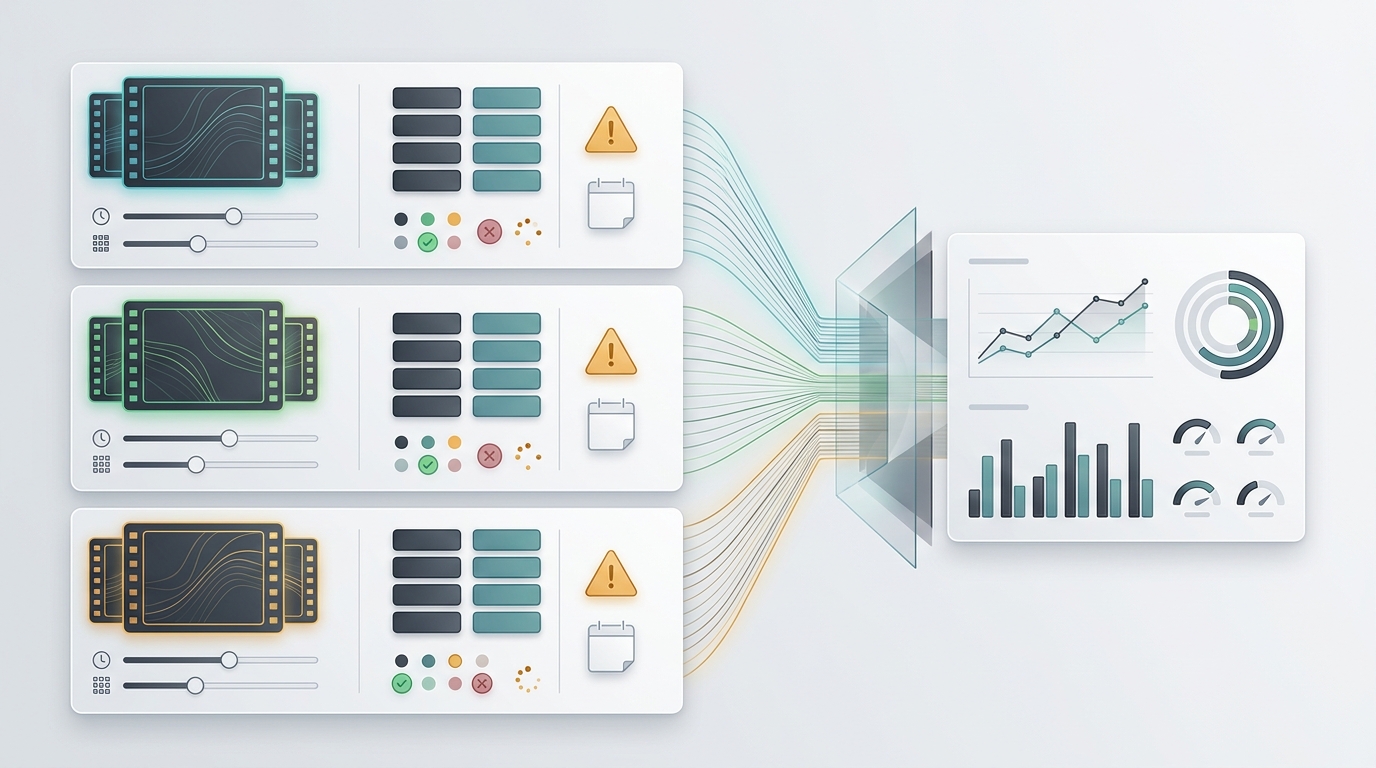
AI Video Generation API Pricing Comparison: Seedance, Veo, and Sora Deprecation Risk
AI video generation API pricing is harder to compare than text or image pricing because the billing unit changes by provider. Google Veo and OpenAI Sora expose per-second video prices, BytePlus Seedance examples are tied to token/resource-pack consumption, and every route has extra operational quest

AI Image Generation API Pricing Comparison: GPT Image, Gemini Image, and Imagen Units
AI image generation API pricing is hard to compare because providers do not all sell the same unit. OpenAI GPT Image uses token-based image cost estimates, Google Gemini image models blend text, input image, and output image token pricing, and Google Imagen is often shown as a direct per-image price
Build faster with one AI gateway.
Use flatkey.ai to manage models, keys, billing, and observability from one API platform.
Get started